Parallel Pipeline
The Parallel Pipeline is a distinguished higher-order pipeline within Syncraft's query engine, designed to execute its child pipelines concurrently. This concurrent execution model significantly enhances query performance, especially in large datasets or computationally intensive operations scenarios. Allowing multiple pipelines to run independently and in parallel optimizes the data processing flow, making it a valuable asset in achieving performance efficiency.
Core Features
1. Concurrent Execution
The cornerstone of the Parallel Pipeline is its ability to execute multiple child pipelines concurrently, thus optimizing system resources and reducing the overall execution time.
2. Independent Processing
Each child pipeline within a Parallel Pipeline operates independently, ensuring that the failure or delay in one does not directly impact the others.
3. Data Processing Efficiency
By distributing the workload across multiple pipelines that run in parallel it significantly enhances the data processing efficiency and speed.
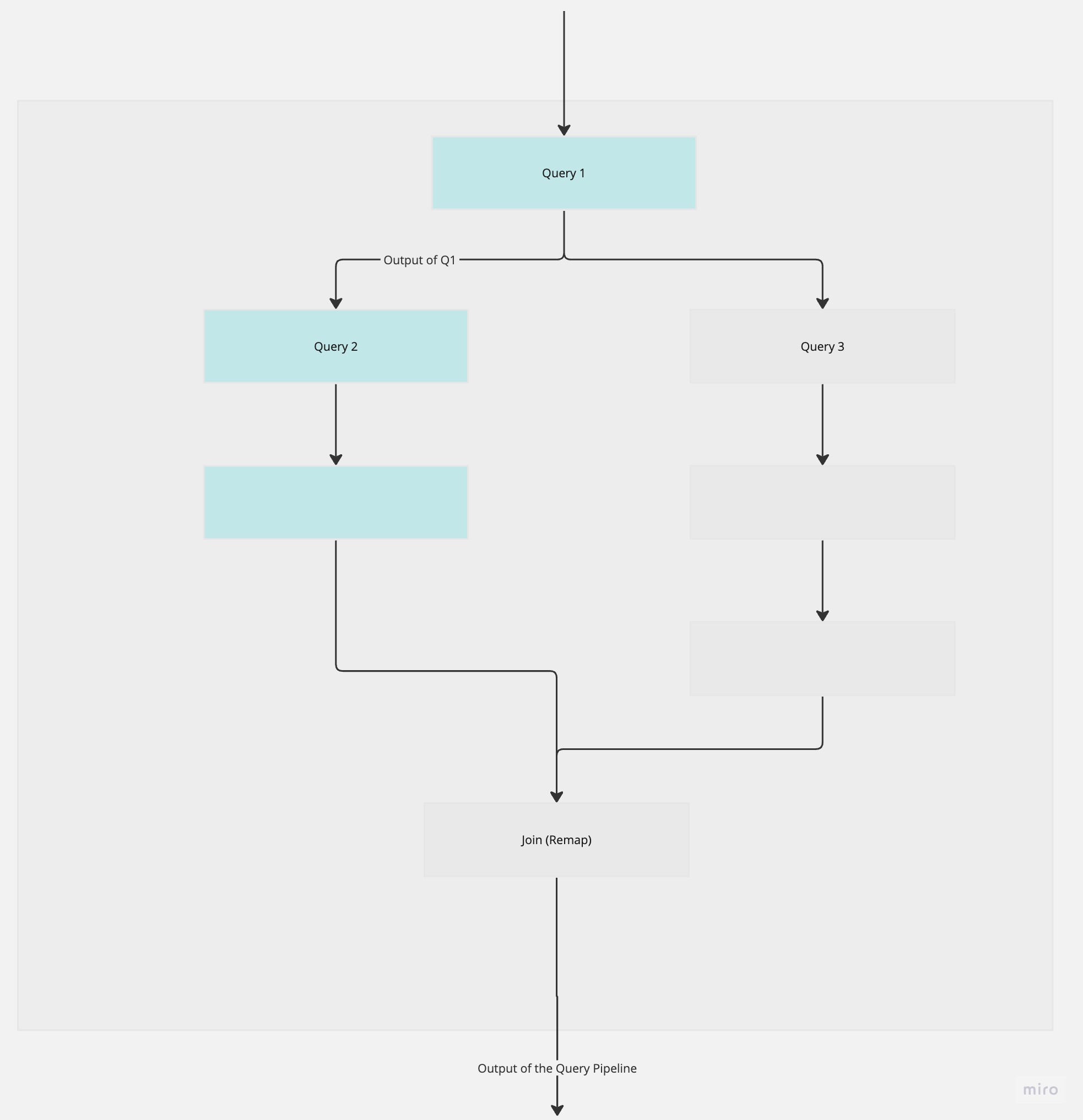
Components
- Collect - A map of the field - pipeline, where after the pipeline completes, the value is stored and can be referenced by a field name in the ReMap step.
- ReMap - The step where we can consolidate the data returned from parallel pipelines. Learn more about ReMap pipelines.
Functional Significance
Scalability:
The Parallel Pipeline introduces scalability in the data processing flow, adapting to varying workloads by distributing the processing tasks.
Performance Optimization:
It plays a critical role in performance optimization, especially in scenarios where time is of the essence or when dealing with large-scale data processing tasks.
Resource Utilization:
Parallel Pipelines promote better resource utilization by concurrently executing multiple pipelines and effectively using the available computational resources.
Usage Scenarios
Large Dataset Processing:
When dealing with large datasets, executing pipelines in parallel significantly reduces the processing time.
Real-Time Data Processing:
In real-time data processing scenarios where low latency is crucial, Parallel Pipelines provide a means to meet such performance demands.
Computationally Intensive Operations:
Distributing the workload across parallel pipelines can provide notable performance benefits for computationally intensive operations.
Conclusion
The Parallel Pipeline is a pivotal construct within Syncraft’s query engine, aligning well with the demands of modern-day data processing challenges. Its concurrent execution model enhances performance and introduces a scalable and efficient approach to handle complex query logic. Equipping parallel processing significantly speeds up data retrieval and transformation tasks, elevating the overall efficiency and effectiveness of data processing workflows in Syncraft.